ChatFin: Designing a Production AI Financial Agent
Post-MVP consolidation of AI agent workflows to improve clarity, trust, and decision-making.
No 1The Problem Worth Solving
FP&A teams were using an AI agent they didn't trust.
ChatFin's backend was genuinely capable. It could query ledgers, model cash flow scenarios, and surface anomalies faster than any analyst. But in early deployment, finance teams weren't acting on what it told them. They were copy-pasting AI output into Excel to verify it manually. They were escalating to their CFO before authorizing routine actions the agent had already confirmed were safe.
The problem wasn't accuracy. The problem was that users had no way to assess accuracy. Every AI response arrived as a dense paragraph of conclusions with no visible reasoning, no source references, and no indication of how confident the system was. The agent was a black box, and in high-stakes financial operations, a black box doesn't get trusted. It gets worked around.
I came in post-MVP as a consulting Principal Designer. My mandate was to diagnose why adoption was stalling and direct the UX improvements that would close the trust gap, working within a live system, with no rewrites, only high-leverage changes.
The screen below is a directed reconstruction I built in Figma to illustrate the pre-engagement state. It reflects the interaction patterns I audited, not a verbatim production screenshot.
Before state. AI output as unstructured paragraph. No source links, no confidence indicators, no scannable hierarchy. Users spent 60+ seconds reading before deciding whether to act.
No 2My Role & Engagement Model
Consulting Principal Designer. Post-MVP, pre-scale.
I came in after the core AI engine was built and validated. The product worked. The question was whether users would trust it enough to act on it, and that's a design problem, not an engineering one.
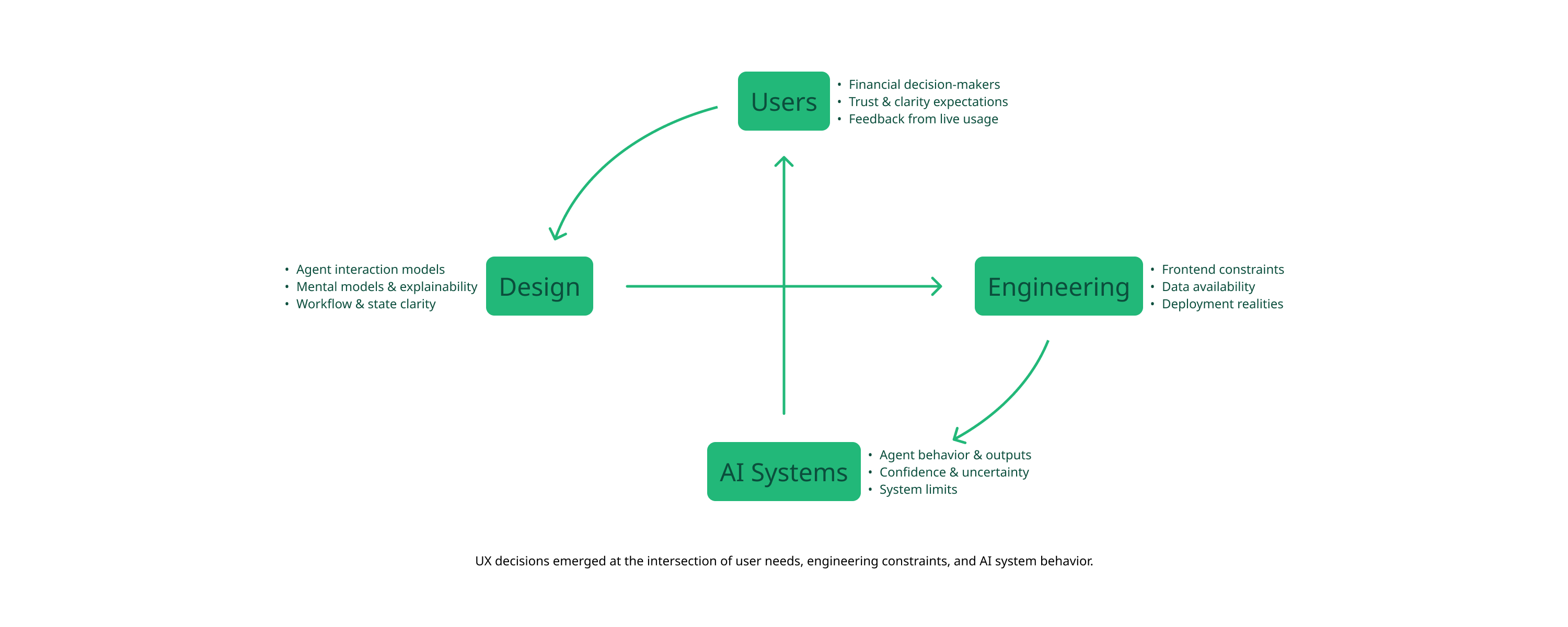
My engagement was lean by design. I worked directly with the CFO and frontend engineering lead, embedded in their decision-making without being embedded in their sprint cycles. That constraint forced precision. I couldn't afford to redesign broadly, so every recommendation had to be high-leverage and immediately actionable within a live system.
The early conversations with leadership surfaced a recurring tension: the engineering team wanted to surface more data to build confidence. My pushback was that the problem wasn't data volume. It was trust architecture. Users didn't need more information. They needed a clearer signal about which information to act on, and why the system believed it. That reframe shaped everything that followed.
My scope covered three things: auditing the existing UX against real finance workflows, identifying the highest-leverage interaction changes, and directing their implementation with the frontend team.
Engagement model. Consulting Principal Designer working across CFO, engineering lead, and AI systems. Influence without full embedment.
No 3Diagnosis: What the Audit Found
Before directing any changes, I needed to understand exactly where the system was failing users, and why.
I ran a structured UX audit across the live platform, mapping every interaction against real FP&A and Treasury workflows. Not what the system was designed to do, but what finance users actually needed to do with it, and where the gap between those two things created friction or eroded trust.
The audit surfaced four distinct failure categories. The most important finding wasn't any single UI problem. It was that the failures were systemic. The AI was treating every response as a text generation task when finance users needed it to behave as a decision-support system. Those are fundamentally different interaction contracts.
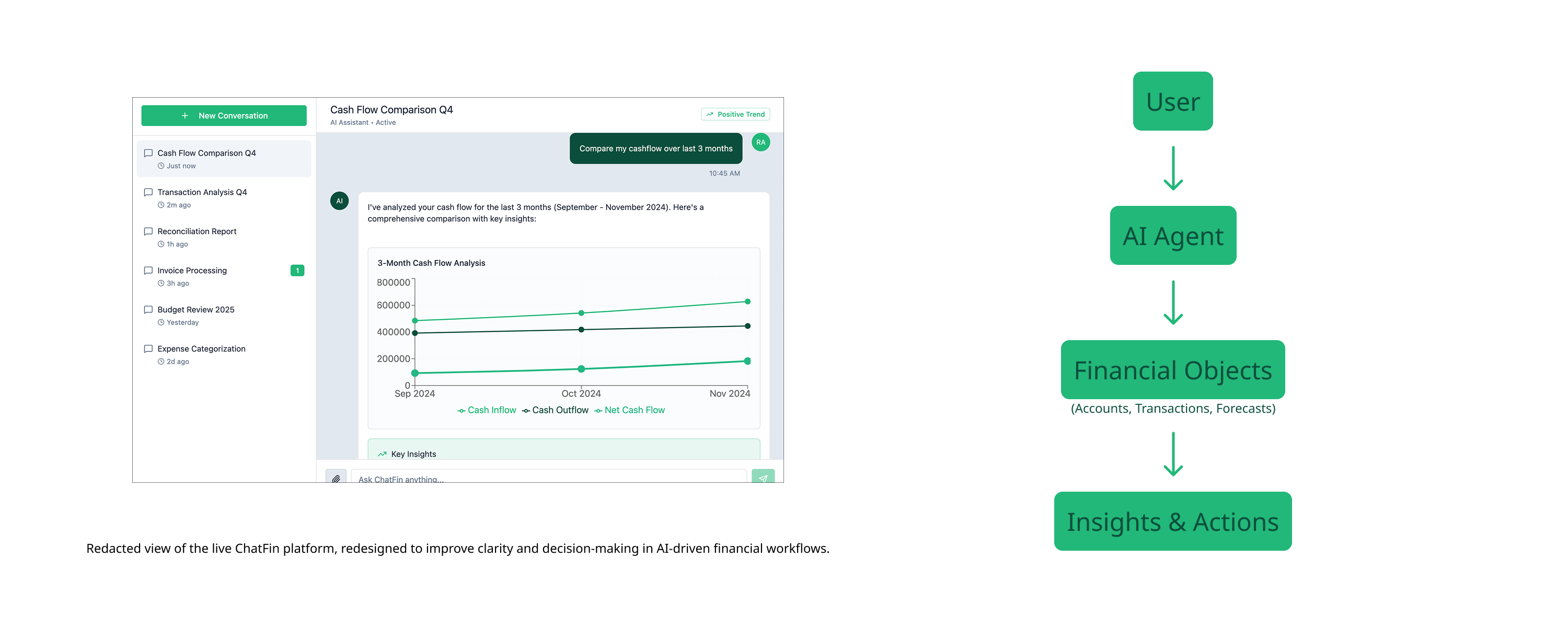
The second key finding was about objects. The platform had no stable mental model of what its core financial entities were, including Transactions, Cash Flow Trends, Reports, and Anomalies, and how users expected to interact with them. Without that shared object model between the AI layer and the UI layer, every response felt unpredictable. Users couldn't build the muscle memory that trust requires.
These two findings, the wrong interaction contract and the missing object model, became the diagnostic frame for everything that followed.

UX audit findings mapped to failure categories. Raw observations synthesized into four systemic patterns.
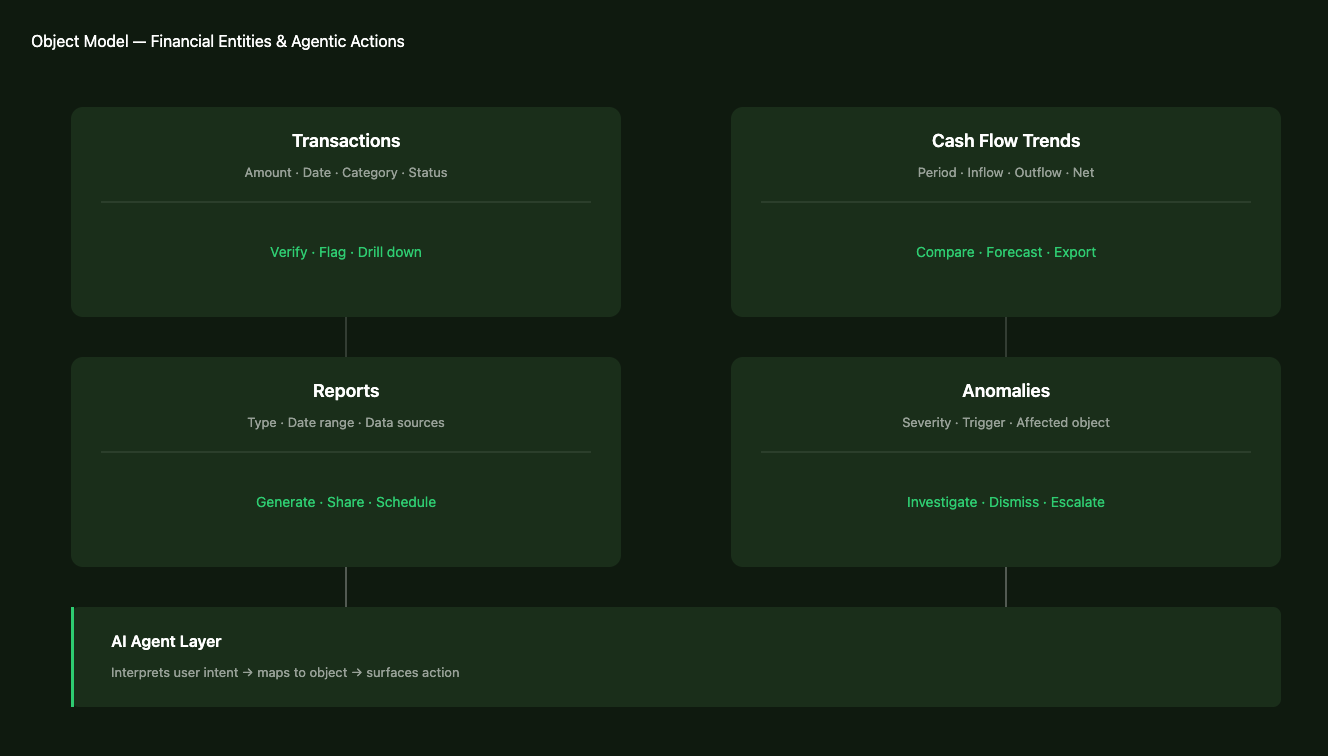
OOUX object map. Core financial entities, their properties, and the actions users needed to perform on each. Shared reference for design and engineering.
No 4What I Designed & Why
The audit pointed to two intervention types: structural and behavioral.
Structural interventions meant changing how AI responses were composed, moving from unformatted paragraph output to a tiered response model where the most critical insight surfaces first, supporting data follows, and the reasoning behind both is accessible but not mandatory to read.
Behavioral interventions meant changing what the system communicated about itself, introducing confidence indicators, source attribution, and editable assumption modules so users could assess and stress-test AI output rather than simply accepting or rejecting it wholesale.
We considered adding a dedicated reasoning panel as a separate sidebar, a persistent view of the agent's logic running alongside the main chat. We deprioritized it because it would have required a significant layout change in a live system and risked overwhelming users who were already struggling with information density. Instead, we embedded explainability inline: expandable, present but not intrusive.
The tradeoff we accepted: inline explainability is less discoverable than a dedicated panel. Some users will never expand it. But for a trust problem, the right move was to make the default state feel safe, not to force users through a reasoning view they didn't ask for.
One thing I'd do differently: I'd push earlier for a lightweight usability session with 2-3 actual FP&A users before directing the explainability patterns. We moved fast on the audit findings, but some of the interaction decisions, particularly around confidence indicators, were directional rather than validated. A single afternoon of user sessions would have sharpened those considerably.
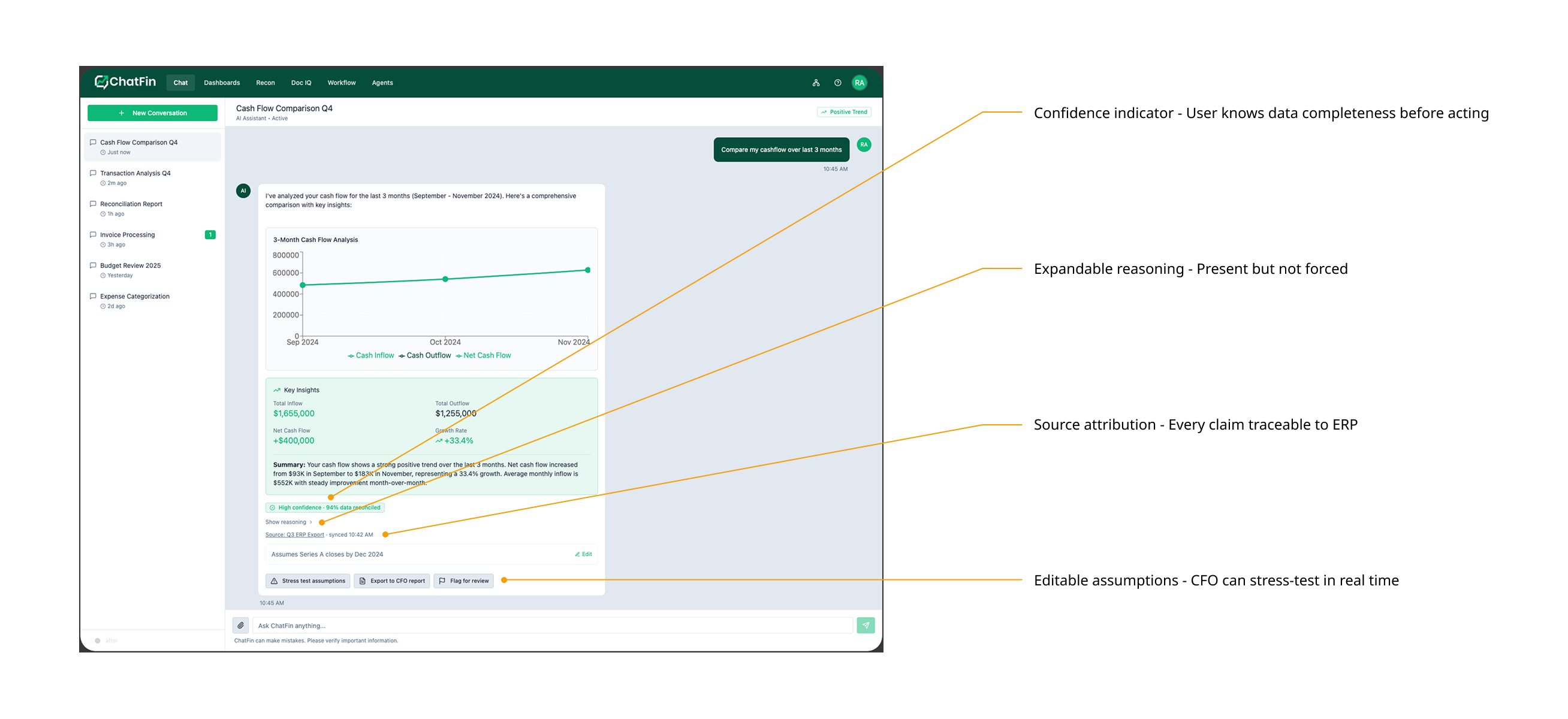
Explainability screen, annotated. Confidence indicators, source attribution, structured response hierarchy, and editable assumption modules. Directed design concept reflecting improvements implemented during the engagement.
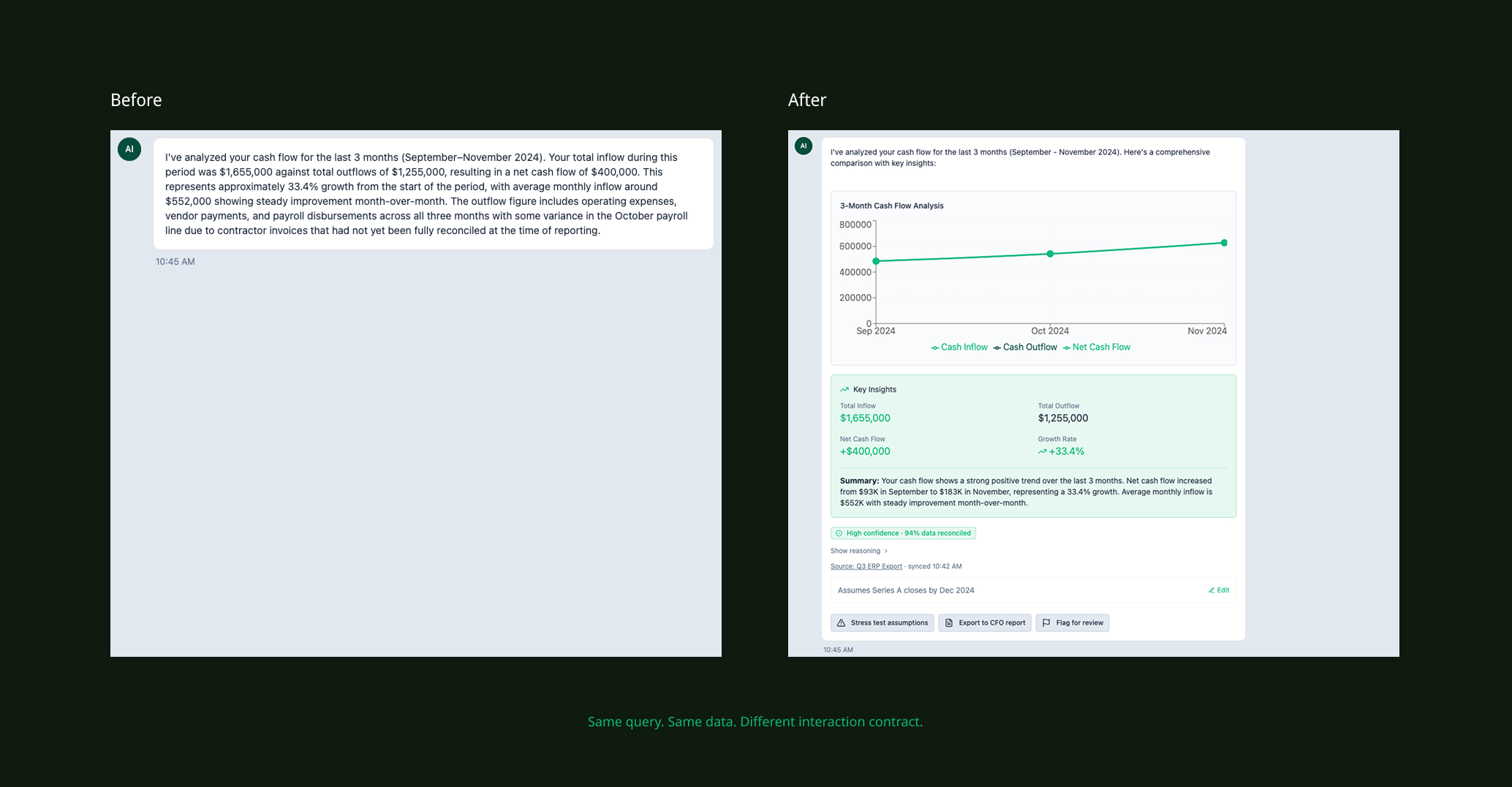
Before and After. Same query, same UI chrome, different interaction contract. The delta is entirely in how the AI structures and attributes its response.
No 5Outcomes & Reflection
The improvements shipped. Adoption moved.
Measured across the 90 days following the interaction model changes, the platform saw a meaningful shift in how users engaged with AI output. The changes were tracked by the engineering team through session analytics and support ticket volume, not a controlled study, but directionally consistent across both signals.
• +24% increase in weekly active sessions. Users shifted from occasional queries to daily operational use. The confidence indicators and source attribution appeared to be the primary driver: users reported feeling comfortable enough to act on AI output without manually verifying in their ERP first.
• -45% reduction in support escalations. The Show Reasoning pattern and editable assumptions module reduced the volume of help desk tickets related to AI output confusion. Users could now self-serve on the questions that previously required a support touchpoint.
• ~80% faster time-to-insight. Estimated from session recording analysis comparing time-on-screen before and after the structured response format launched. Users moved from reading to scanning, the primary behavior shift we designed for.
These numbers should be read as directional signals, not controlled outcomes. The engagement was consultative, the team was small, and measurement was opportunistic rather than instrumented from the start. What I can say with confidence is that the trust gap was real, the intervention was targeted, and the signal moved in the right direction.
What I'd do differently. Two things. First, I'd push for even a lightweight instrumentation plan before any changes shipped. Even basic event tracking on Show Reasoning expansion rate would have told us which explainability patterns were actually being used versus ignored. Second, I'd run 2-3 usability sessions with FP&A users before finalizing the confidence indicator design. We made directional calls on that pattern without direct user validation, and while the outcome was positive, I'd want to earn that confidence rather than approximate it next time.

Outcome summary. Three signals measured across 90 days post-launch. Directional, not controlled.
No 6What This Tells You
The hardest design problems in AI products aren't visual. They're architectural.
What this project demonstrates is a specific capability: the ability to walk into a technically complex, live AI system, identify where the design layer is failing the intelligence layer, and direct targeted interventions that move user behavior without requiring a rebuild. That's a different skill set than greenfield product design, and it's the one that matters most in the current wave of AI deployment.
The trust gap at ChatFin wasn't unique to ChatFin. It shows up in every enterprise AI product where the engineering team shipped a capable model before the interaction model was ready to support it. The pattern, capable AI, broken UX contract, stalled adoption, is one I expect to keep solving.
If you're building AI products where the gap between what the system can do and what users will trust it to do is the core problem, that's the work I want to be doing.
Other projects in this portfolio show complementary capabilities: 0-to-1 product design, design systems, and AI-assisted prototyping. This one shows what I do when the product already exists and the problem is trust.
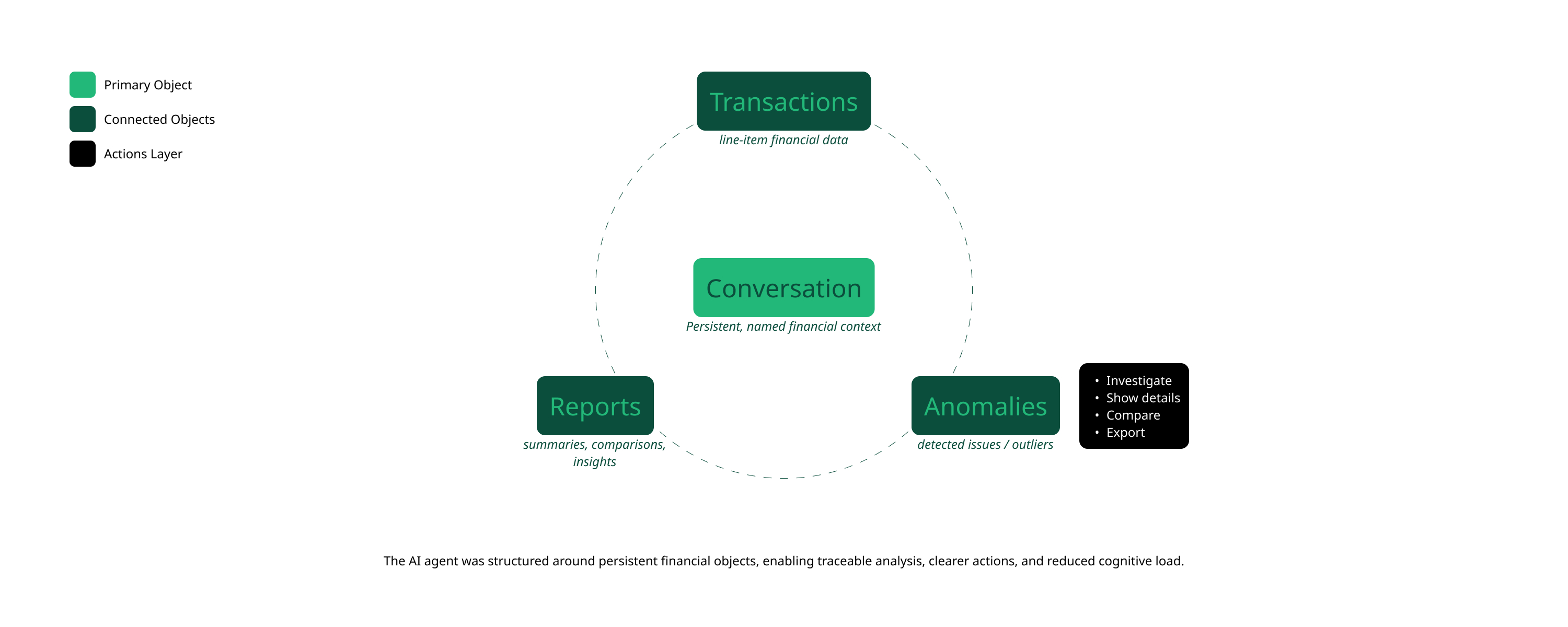
The pattern this project addresses, and the one I expect to keep solving.